فایل robots.txt یک فایل متنی است که توسط آن امکان تعریف برخی قوانین برای ربات های موتور جستجو وجود دارد. قوانینی مانند محدود کردن ربات موتور جستجو برای دسترسی به فایل، دایرکتوری، منابع مانند عکس و CSS و js، صفحه و کل سایت وجود دارد. بیشتر موتورهای جستجو مطرح مانند گوگل، بینگ، یاهو و یاندکس از robots.txt پشتیبانی می کنند و توسط آن می شود قوانینی را برای موتورهای جستجو مشخص کرد.
نکات ایجاد و آپلود robots.txt
برای ایجاد فایل robots.txt استانداردهای مختلفی وجود دارد. موتور جستجوی گوگل از استاندارد Robots Exclusion Protocol RFC 9309 که در سال ۱۹۹۴ منتشر شد پشتیبانی می کند. در ادامه در مورد نکاتی که لازم است برای ایجاد robots.txt مورد توجه قرار گیرد توضیح داده شده است:
- فایل robots.txt باید به صورت UTF-8 ذخیره شده باشد.
- فایل robots.txt فقط می تواند در روت سایت و با آدرسی مانند https://www.example.com/robots.txt در دسترس باشد. در صورتی که robots.txt در آدرسی مانند https://www.example.com/directory/robots.txt وجود داشته باشد، توسط موتورهای جستجو خوانده نخواهد شد.
- نام فایل robots.txt باید به حروف کوچک نوشته شود.
- اگر دو rule در مورد یک مسیر یا یک فایل وجود داشته باشد، آن قانونی که دقیق تر است مد نظر گرفته خواهد شد.
- قوانینی که در robots.txt نوشته می شود به صورت <field>:<value> است.
- <field> به حروف کوچک و بزرگ حساس نیست. بنابراین Allow و allow و ALLOW و AlloW یکسان هستند.
- <value> به حروف کوچک و بزرگ حساس است.
- بعد از کاراکتر دو نقطه : می تواند یک کاراکتر space وجود داشته باشد.
- سایز فایل robots.txt نباید از 500KB بیشتر باشد. اگر سایز فایل بیشتر از 500KB باشد، گوگل فقط 500KB ابتدای فایل را مد نظر می گیرد.
- ترتیب نوشتن قوانین اهمیت ندارد. به عبارت دیگر، قانونی که در خط اول نوشته شده است، اولویتی نسبت به قوانین خطوط بعدی ندارد و در صورت داشتن وجه مشترک ، آن قانونی در نظر گرفته می شود که دقیق تر باشد.
- robots.txt نمی تواند مانع از ورود خزنده موتور جستجو از سایت دیگری که به سایت شما لینک داده بشود.
- صرف نظر از وجود یا عدم وجود کامنت، خط اول robots.txt با user-agent شروع می شود.
- گوگل معمولا محتوای robots.txt را به مدت ۲۴ ساعت کش می کند. در صورتی که فایل robots.txt شما آپدیت شده و قصد دارید که گوگل سریع تر آن را بخواند، از ابزار robots.txt Tester در سرچ کنسول استفاده کنید.
- robots.txt روی پروتکل، دامین یا سابدامین و پورتی که در دسترس است اعمال می شود. به عنوان نمونه، در robots.txt با آدرس https://example.com/robots.txt نمی شود قوانینی برای آدرس هایی که در سابدامین https://m.example.com هستند نوشت.
- بیشتر موتورهای جستجو فایل robots.txt را با یکی از پروتکل های HTTP یا HTTPS می توانند بخوانند ولی گوگل از پروتکل FTP نیز پشتیبانی می کند. بنابراین برای یک صفحه با پروتکل FTP نیز امکان داشتن فایل robots.txt وجود دارد به شرطی که برای دسترسی به آن به نام کاربری و کلمه عبور FTP نیازی نباشد.
- کاراکتر $ به معنی ختم شدن آدرس به عبارتیست که در rule نوشته شده است. به عنوان نمونه *.js$ به معنی همه آدرس هایی است که به .js ختم شوند.
- برای نوشتن کامنت در robots.txt از کاراکتر # استفاده کنید.
User-agent: *
Disallow: /wp-admin/ # This is a comment
Allow: /*.css$
# This is another commentrobots.txt چه محدودیت هایی می تواند داشته باشد؟
جهت استفاده از robots.txt برای اعمال محدودیت در ترافیک crawl سایت، نکات زیر را مد نظر داشته باشید:
- robots.txt ممکن است توسط همه موتورهای جستجو پشتیبانی نشود. همچنین ممکن است برخی قوانین robots.txt نیز توسط همه موتورهای جستجو پشتیبانی نشود.
- robots.txt نمی تواند برای موتورهای جستجو یک قانون اجباری را تعریف کند و تبعیت کردن یا نکردن به قانون نوشته شده در robots.txt بستگی به موتور جستجو دارد.
- در صورتیکه یک صفحه یا دایرکتوری را از طریق robots.txt بر روی خزنده موتور جستجو مسدود کرده باشید، ممکن است خزنده موتور جستجو از روش های دیگر مانند یک لینک خارجی به آن صفحه دسترسی پیدا کرده و آن را ایندکس کند. در صورتیکه قصد دارید مانع از ایندکس شدن یک صفحه شوید، از روشی مانند متا تگ ربات noindex یا X-Robots-Tag در HTTP response header استفاده کنید و یا دسترسی به آن صفحه را توسط نام کاربری و کلمه عبور محدود کنید.
از چه قوانینی در robots.txt می شود استفاده کرد؟
در فایل robots.txt می شود از فیلدهای user-agent، allow، disallow و sitemap استفاده کرد که در ادامه در مورد آنها توضیح داده شده است.
user-agent
هر قانونی که در robots.txt وجود داشته باشد، باید با user-agent شروع شود. مقدار user-agent برابر با نام (استرینگ) ربات های موتور جستجو یا هر رباتی که از robots.txt پشتیبانی می کند است. به عنوان نمونه گوگل برای crawl صفحات و جستجوی متنی از یوزر ایجنت Googlebot و برای crawl عکس صفحات از یوزر ایجنت Googlebot-Image استفاده می کند.
در صورت استفاده از مقدار * به عنوان یوزر ایجنت، قوانینی که در ادامه آن نوشته شده، خطاب به همه ربات هایی است که از robots.txt پشتیبانی می کنند.
User-agent: *
Disallow: /foo/
User-agent: Googlebot
User-agent: Adsbot-Google
Disallow: /bar/
User-agent: Googlebot-Image
Disallow: /uplaodes/*.jpg$
Allow: /uplaodes/*.png$
User-agent: Twitterbot
User-agent: facebookexternalhit
Allow: /uplaodes/*.png$
برای آشنایی بیشتر با ربات های مختلف گوگل، نوشته انواع گوگل بات را مطالعه نمایید.
disallow
با استفاده از Disallow می توانید صفحه یا مسیر، صفحه یا منبعی را که می خواهید بر روی ربات موتور جستجو مسدود کنید را مشخص نمایید.
User-agent: *
# Disallow: [فایل یا مسیر مورد نظر]
Disallow: /articles/
Disallow: /products/product1.html
Disallow: /*.pdf$
allow
اگر از disallow استفاده نشده باشد، گوگل بات اجازه دسترسی به همه آدرس ها را دارد. ولی با استفاده از Allow می توانید برای یک صفحه، مسیر و منبع، از درون مسیری که بر روی خزنده موتور جستجو مسدود کرده بودید استثنا قائل شوید و به موتور جستجو اجازه بدهید آن را بخواند و ایندکس کند.
User-agent: *
# Allow: [فایل یا مسیر مورد نظر]
Allow: /articles/seo/
Allow: /products/product2.html
Allow: /*.css$
sitemap
با استفاده از sitemap می توانید مسیر نقشه(های) سایت را برای موتور جستجو مشخص نمایید. همه موتورهای جستجو از sitemap در فایل robots.txt پشتیبانی نمی کنند. البته علاوه بر گوگل، موتورهای جستجوی بزرگ مانند Bing نیز از sitemap در فایل robots.txt پشتیبانی می کنند.
User-agent: *
# Sitemap: [آدرس سایت مپ]
Sitemap: https://www.example.com/sitemap1.xml
Sitemap: https://www.example.com/sitemap2.xml
آدرس سایت مپ هایی که در robots.txt قرار دارند باید به صورت absolute باشد. گوگل سایت مپ های با آدرس های relative را نادیده می گیرد. بنابراین آدرس https://www.example.com/sitemap1.xml صحیح است و آدرس /sitemap1.xml اشتباه است.
اگر آدرس سایت مپ یا سایت مپ های سایتتان را در robots.txt قرار دهید، کاربران نیز می توانند به اطلاعات صفحات شما دسترسی داشته باشند. بنابراین اگر به هر دلیلی قصد داشته باشید که آدرس سایت مپ های سایت شما محرمانه باشد، این کار را انجام ندهید و سایت مپ را در سرچ کنسول ثبت کنید.
چند نمونه استفاده از robots.txt
جهت نوشتن robots.txt از دستورات متعددی می توان استفاده نمود که در جدول زیر تعدادی از آنها به عنوان نمونه نمایش داده شده است.
| توضیح | Rule |
|---|---|
| مانع از دسترسی به همه سایت می شود | Disallow: / Disallow: /* |
| مانع از دسترسی به یک دایرکتوری به همراه همه محتویاتش | Disallow: /directory/ |
| مانع از دسترسی به هر صفحه ای با نام page.html که بعد از یک slash باشد. | Disallow: /page.html |
| یک عکس مشخص بر روی ربات جستجوی عکس گوگل مسدود شده | User-agent: Googlebot-Image Disallow: /images/dogs.jpg |
| همه سایت بر روی ربات جستجوی عکس گوگل محدود شده | User-agent: Googlebot-Image Disallow: / |
| اجازه دسترسی به همه آدرس هایی که در انتهای آنها .css باشد وجود دارد | Allow: /*.css$ |
| مانع از دسترسی به هر دایرکتوری که ابتدای نام آن private باشد به همراه محتویاتش می شود. | Disallow: /private*/ |
| مانع از دسترسی به هر آدرسی که در آن علامت سوال وجود دارد می شود. | Disallow: /*? |
| مانع از دسترسی به هر آدرسی که با علامت سوال پایان یابد می شود. | Disallow: /*?$ |
تست robots.txt
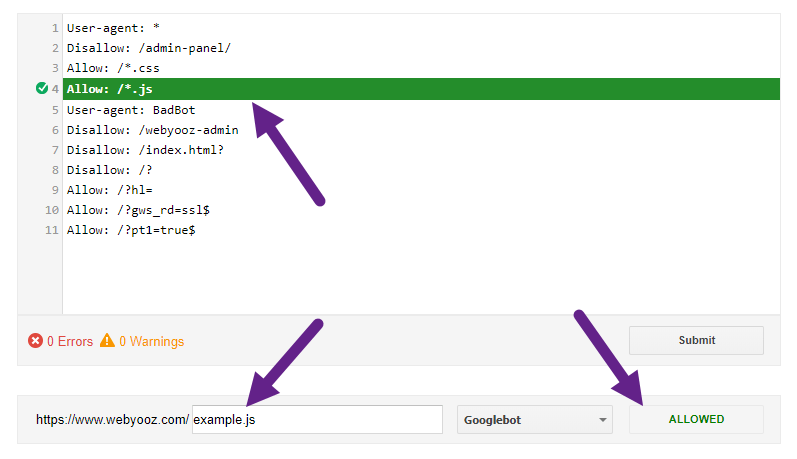
جهت بررسی بلاک بودن یا نبودن یک آدرس، یک منبع یا مسیر بر روی گوگل بات، ابتدا صفحه ابزار robots.txt Tester سرچ کنسول را باز کرده و سپس آدرس مورد نظرتان را مانند تصویر زیر در فیلد مربوطه نوشته و پس انتخاب user-agent از منوی آبشاری، روی دکمه TEST کلیک کنید. اطلاعات بیشتر در صفحه ابزار robots.txt Tester در سرچ کنسول وجود دارد.
پرسش های متداول در مورد robots.txt
داشتن robots.txt برای سایت ها اجباری نیست. وقتی گوگل بات می خواهد یک سایت را crawl کند، ابتدا robots.txt آن را چک می کند و اگر موجود بود، از قوانینی که در آن نوشته شده تبعیت می کند.
کاربرد robots.txt برای کنترل crawl است و به معنی کنترل indexing نیست. بیشتر صفحاتی که با robots.txt به روی گوگل مسدود شده اند، ایندکس نمی شوند ولی ممکن است گوگل از طریق یک لینک خارجی وارد آن صفحه شود و بدون توجه به robots.txt، آن را ایندکس کند.
خیر. به صورت پیشفرض همه آدرس ها allow هستند. اما اگر مسیری disallow شده است و قصد دارید یک مسیر یا آدرس را از درون آن آدرس allow کنید، نیاز است که از allow استفاده شود.
برای ایجاد فایل robots.txt نیازی به نرم افزار خاصی نیست. می توانید از هر ادیتور متنی مانند Notepad در ویندوز و vi در لینوکس و Emacs در مک که خروجی txt با انکودینگ UTF-8 بدهد استفاده کنید.
در فایل robots.txt همه آدرس ها باید به صورت UTF-8 باشند. بنابراین به عنوان نمونه به جای کلمه “کتاب” در آدرس، از “%DA%A9%D8%AA%D8%A7%D8%A8” استفاده کنید.
خیر. موتورهای جستجوی مطرح از robots.txt تبعیت می کنند ولی ممکن است ربات هایی وجود داشته باشند که بدون در نظر گرفتن قوانینی که در robots.txt وجود دارد، سایت را کراول کنند.
خیر، robots.txt برای اعمال محدودیت روی IP address نیست و کاربردش صرفا وضع قوانین برای ربات هایی است که از آن پشتیبانی می کنند.
🔗 منبع: Google Developers